In this work, we introduce ClimaGen, an adaptive learning framework for creating benchmarks to evaluate large language models (LLMs) on scientific question-answering (QA) tasks, specifically in climate science. ClimaGen synthesizes QA datasets by leveraging LLMs to generate base-level questions from graduate-level textbooks, refining them through expert validation to ensure scientific rigor. Using this framework, we develop ClimaQA, a novel benchmark comprising two datasets: ClimaQA-Gold (566 expert-annotated questions) and ClimaQA-Silver (3,000 synthetic questions for large-scale fine-tuning).
Our benchmark evaluates LLMs across three QA task formats (multiple-choice, freeform, and cloze), challenging models on factual recall, scientific reasoning, and scenario-based applications. Through our experiments, we observe that most models struggle with reasoning-based questions and that Retrieval-Augmented Generation (RAG) significantly outperforms traditional fine-tuning approaches. Our key contributions include:
Creation of ClimaQA, a publicly available dataset for climate science QA.
Development of ClimaGen, a scalable, expert-in-the-loop framework for scientific benchmark creation.
Evaluation of state-of-the-art LLMs, providing insights into improving scientific accuracy in climate-related tasks.
The ClimaQA benchmark is designed to evaluate Large Language Models (LLMs) on climate science question-answering tasks by ensuring scientific rigor and complexity. It is built from graduate-level climate science textbooks, which provide a reliable foundation for generating questions with precise terminology and complex scientific theories. The benchmark consists of two datasets: ClimaQA-Gold, an expert-validated set, and ClimaQA-Silver, a large-scale synthetic dataset.
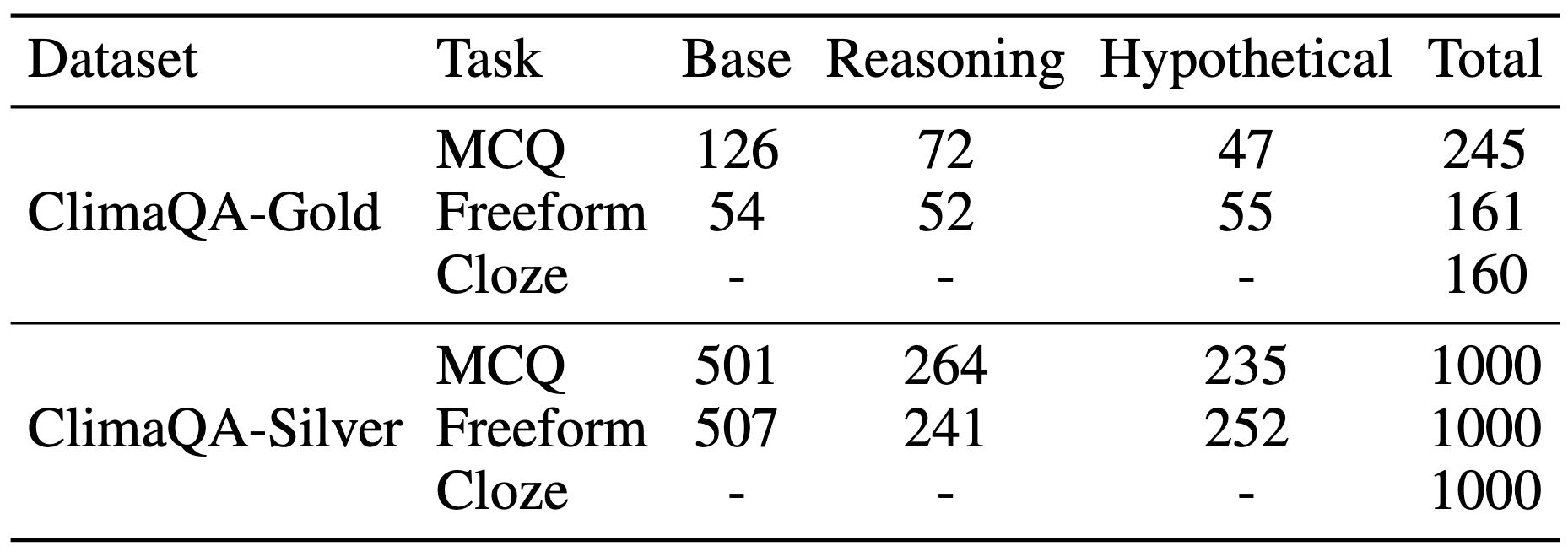
To comprehensively assess model performance, we structure questions across three levels of complexity:
Base: Basic questions that test direct knowledge retrieval.
Reasoning: Questions requiring logical connections between multiple scientific concepts.
Hypothetical Scenario: Complex questions that challenge models to apply scientific knowledge in novel contexts.

The benchmark includes three question-answering task formats:
Multiple-Choice (MCQ): Tests factual accuracy and decision-making within structured constraints.
Freeform QA: Evaluates a model’s ability to generate detailed, well-reasoned responses.
Cloze QA: Measures contextual understanding and precise usage of domain-specific vocabulary.

Although assessing multiple-choice question-answering is relatively simple, the other two tasks present more challenges. To address this, we propose and validate the following evaluation metrics for freeform and cloze question-answering.
For Freeform QA, we use BLEU and BERTScore for surface-level and semantic similarity. However, these do not ensure factual correctness. To address this, we introduce a Factual Accuracy metric based on the confidence score of a factual entailment classifier (GPT-4o-mini), which determines whether a generated answer supports a reference answer. This method enhances evaluation by focusing on scientific accuracy rather than just linguistic similarity. Below is the prompt for the LLM-based classifier:

Since exact word matching is often too restrictive, we supplement the Exact Match metric with a Phrase Similarity metric that evaluates whether the generated answer is contextually appropriate, even if it differs from the reference answer. By embedding and comparing phrases within a defined context window using cosine similarity, we ensure a more nuanced assessment of model accuracy, especially in cases where multiple scientifically valid answers exist.
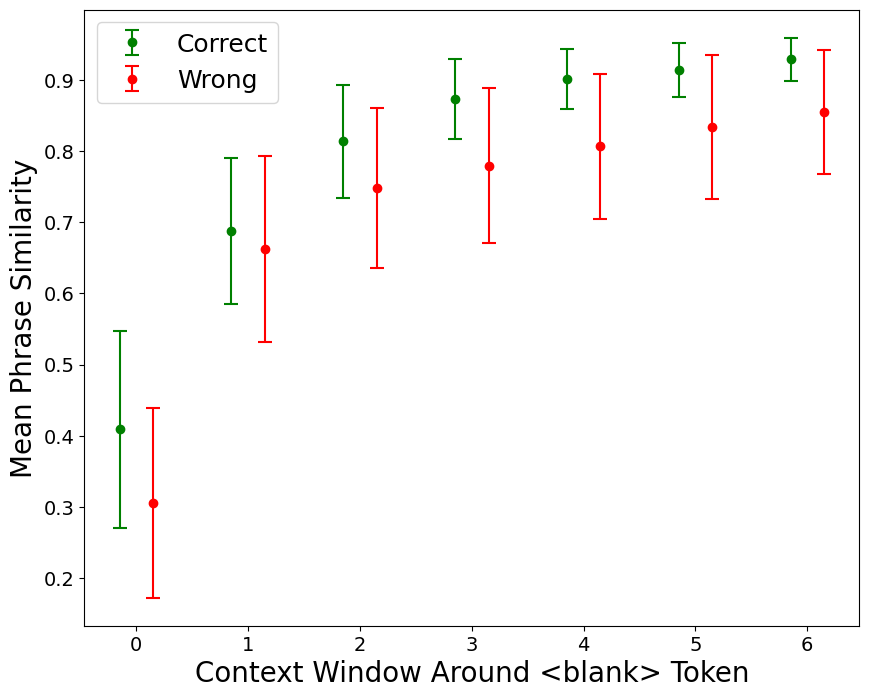
Mean Phrase Similarity for correctly answered and incorrectly answered cloze questions
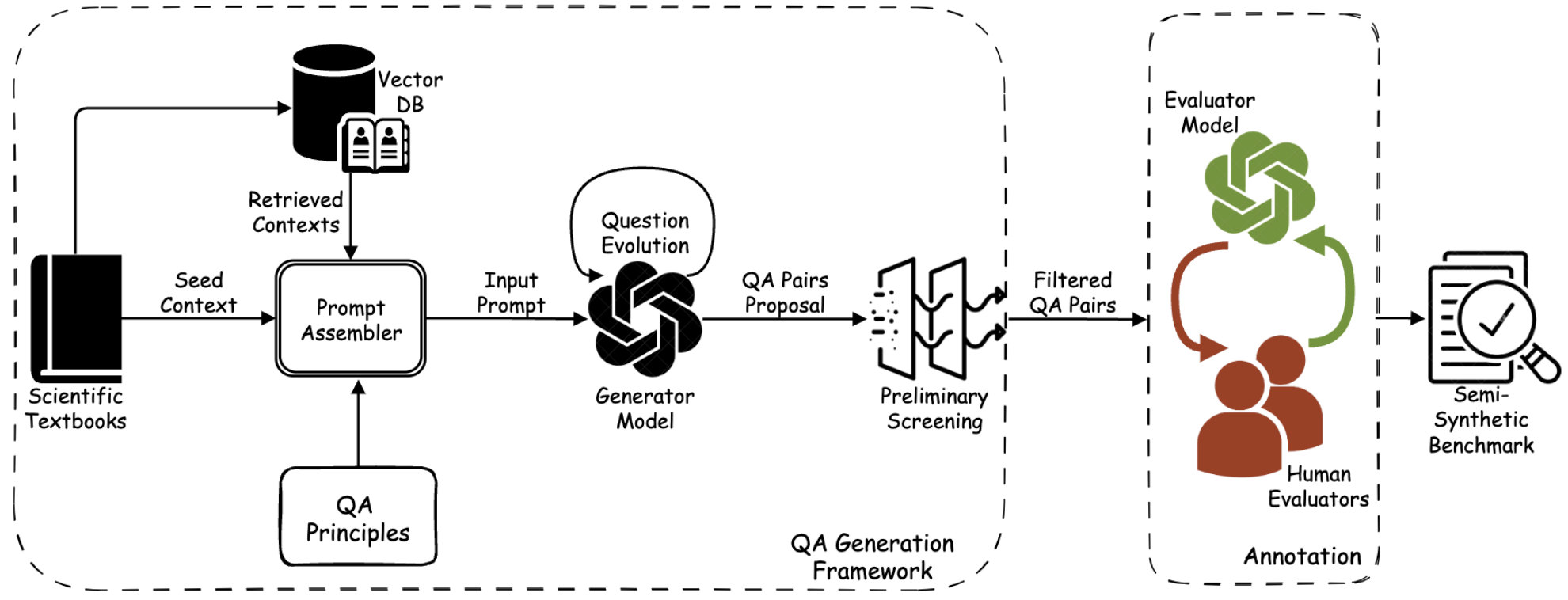
ClimaGen is a framework designed to create the ClimaQA dataset from climate science textbooks by leveraging retrieval-augmented generation (RAG) and prompt engineering. The process involves selecting relevant content from graduate-level climate textbooks, ensuring the use of precise scientific terminology and theories. GPT-3.5-turbo generates a diverse set of questions, including multiple-choice, freeform, and cloze questions of varying complexity. These questions are then refined and validated through human annotation, resulting in the creation of the ClimaQA-Gold dataset, which is rigorously reviewed by domain experts.
To scale the creation of high-quality data, an evaluator LLM (GPT-4o-mini) is fine-tuned on expert-annotated data to automatically validate and refine question-answer pairs. By using uncertainty-based active sampling, the evaluator improves the quality of the generated questions, allowing the production of the ClimaQA-Silver dataset at scale. This semi-automated approach ensures the generation of high-quality synthetic data, ideal for fine-tuning and evaluating AI models in complex scientific question-answering tasks.
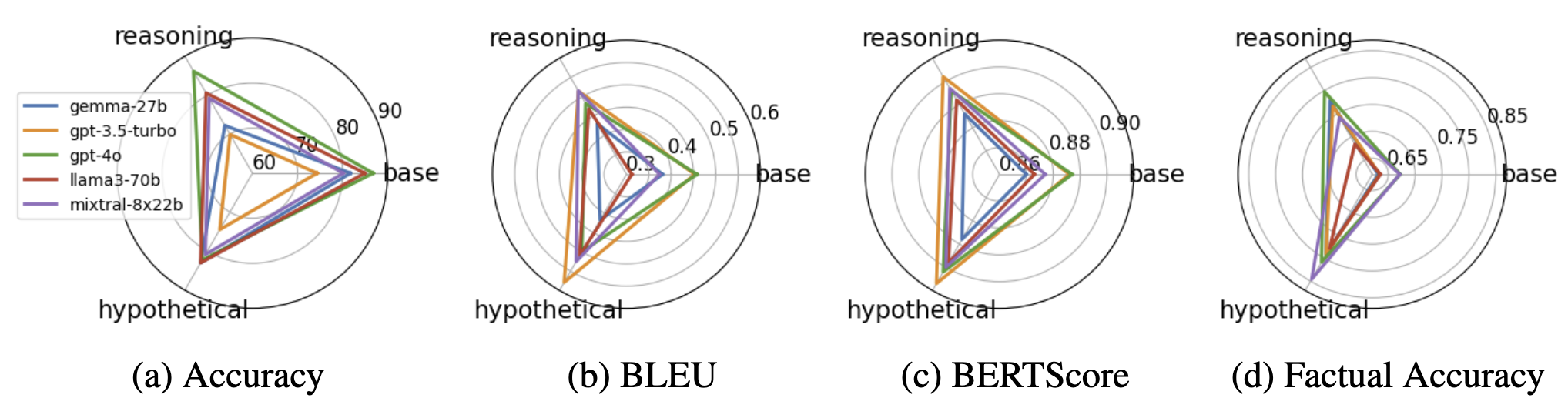
Analysis of various LLMs under default setting on different tasks and different complexities. The first figure shows accuracy of models in the MCQ task while the others show different metrics under the Freeform task
The study evaluates different adaptation techniques for improving LLM performance on fine-grained scientific question answering. It compares fine-tuning, few-shot prompting, and retrieval-augmented generation (RAG) across multiple state-of-the-art LLMS. Key findings include:
Models struggle with reasoning in MCQ but not so in Freeform: While LLMs face challenges in multiple-choice reasoning questions, they perform significantly better in freeform QA, which aligns with prior research on Chain of Thought prompting.
RAG outperforms all knowledge enhancement methods: Among various adaptation techniques, RAG provides the most substantial performance boost by retrieving relevant source materials.
BLEU and BERTScore favor the generator model, while Factual Accuracy does not: Traditional text similarity metrics (BLEU, BERTScore) often favor generator models, but factual accuracy measures reveal discrepancies in correctness.
Overall, GPT-4o generalizes well and dominates in all tasks: GPT-4o consistently outperforms other models across multiple QA formats, showcasing superior generalization abilities.